2. tyden s GeeBun!
Tak mam dalsi tyden za sebou … bohuzel jsem nemel tolik casu co jsem si myslel, a tak porad nemam dodelany hlavni funkcnosti … takze porad jedu na trafficu z *.domain.name, namisto z parkingu.
Novy vzhled
Podarilo se mi od minule konecne upgradnout na novou sablonu. Myslim, ze vypada vyrazne lip jak ta predchozi 🙂
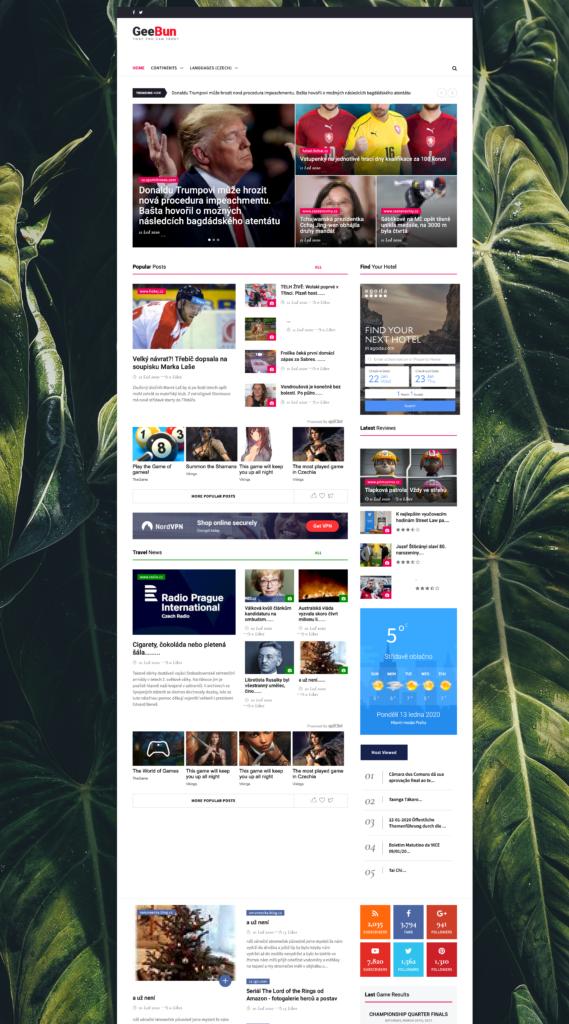
Upravil jsem i data od AcuWeather aby se nacitalo misto aktualniho pocasi rovnou celych 5 dalsich dni 🙂 Poridil jsem API k fotbalovym statistikam, takze budu zobrazovat rovnou i sportovni vysledky lidem podle toho odkud jsou. Upravil jsem generovani obrazku, a to tak aby nejen zmenil velikost, ale pripadne ho i orizl v rezimu center-center, takze mam konecne vsechny obrazky spravne velike. Protoze me tam vylezalo strasne moc clanku ze Sputniku a Hokej.CZ, upravil jsem cely algoritmus tak, aby vzdy v ramci jedne sady zobrazil maximalne 2 prispevky z jednoho webu, cimz jsem docilil ruznorodosti. V menu jsem mel prehled kontinentu ktery vedl na dilci stranky, kde byl prehled jednotlivych statu a dali se pak rozkliknout “zpravy” tykajici se techto statu. V novem designu jsem vyuzil multi-menu a staty vygeneroval rovnou do nej, takze se k tomu da lepe dostat a i na webu to nevypada tak zle.
Afilliate
Co se tyce Afillate a reklam, tak aktualni stav je takovy:
- cj.com mam 5 partneru schvalenych, ale zatim rotuju jen dva bannerey
- Booking jsem vyhodil a vyzkousel Agodu
- Nasadil jsem AdCash a ExoClick
- Google me zamitnul jak se dalo cekat
Ziskovost projektu je hluboko za dnem 🙂
AdCash: 2.08 USD
ExoClick: 1.48 EUR
Na ostatnich ani cent 🙂 Ale tak nejak porad nemam optimalizaci co bych chtel, takze me to netrapi – ze to je cesta na delsi trat jsem vedel uz v zacatcich, tak uvidime.
Podklady
Aktualne mam nacteno pres 200 milionu clanku, coz si myslim ze je dobry zaklad na generovani webu. Kazdou hodinu zpracovavam novinky z TOP 100k zdroju. Jednou za dva se pak snazim pregenerovat plnou palbu ze vsech nekolika desitek milionu RSS zdroju. Aby to slo rychle poridil jsem si na to Amazon EC2 serverik, ale musim poladit nejaky API na zapinani/vypinani, nebot s aktualni cenou za provoz nebude GeeBun! nikdy ziskovy 😀
Vystupy
Pridal jsem ukladani statistik pouzivanych jazyku, navstevovanych stranek a kliku na zdrojove adresy (to jen abych vedel kolik lidi jsem poslal na puvodni weby). Abych s tim mohl jednoduseji pracovat, udelal jsem si k tomu administraci. Na screenshotu je pak videt napriklad prehled TOP 100 navstevovanych clanku:
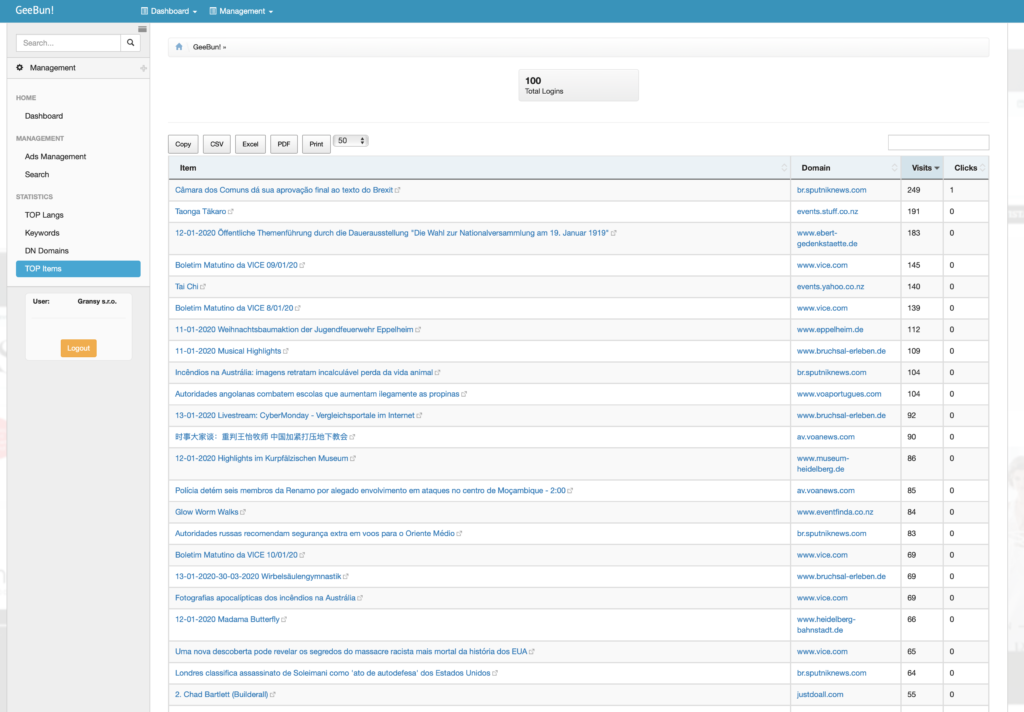
Co bylo velice dulezite, podarilo se mi dat dohromady keyword generator z textu. Je to Pythonni aplikace ktera mi nasloucha jako webserver – poslu ji retezec a jazyk a ona mi vrati jednotliva slova. Aktualne mam k dispozici slovniky EN, PT a CS vuci kterym detekuji klicova slova. A protoze mam statistiky, tak se pochlubim o TOP 50 🙂 Keywordy jsou generovany z navstiveny domeny, pozadovany URI a Referera.
| Keyword | Lang | Count |
|---|---|---|
| film | en | 1825 |
| public | en | 1297 |
| service | en | 1165 |
| cover | en | 1142 |
| token | en | 1127 |
| content | en | 1090 |
| online | en | 1000 |
| view | en | 966 |
| post | en | 938 |
| user | en | 934 |
| time | en | 929 |
| query | en | 892 |
| list | en | 860 |
| images | en | 818 |
| files | en | 778 |
| show | en | 760 |
| rand | en | 729 |
| secret | en | 711 |
| source | en | 690 |
| info | en | 688 |
| blur | en | 685 |
| android | en | 675 |
| grande | en | 667 |
| movie | en | 662 |
| music | en | 661 |
| camp | en | 641 |
| lang | en | 631 |
| image | en | 616 |
| write | en | 609 |
| ounce | en | 600 |
| timely | en | 570 |
| mexican | en | 565 |
| ajax | en | 562 |
| weather | en | 549 |
| cafe | en | 544 |
| media | en | 542 |
| detail | en | 520 |
| game | pt | 519 |
| ogle | en | 516 |
| amos | en | 515 |
| maple | en | 500 |
| movies | en | 488 |
| units | en | 482 |
| file | en | 480 |
| metric | en | 480 |
| mundial | pt | 477 |
| desafio | pt | 473 |
| version | en | 473 |
| cruce | en | 470 |
Tak uz budu moc brzy resit optimalizaci designu dle KW … doufam
Neco bokem
Kdyz uz mam 200M RSS clanku v ES clusteru, statistiky z webu a administraci kam jsem si pridelal vyhledavani, vzpomnel jsem si na svoji drivejsi domeny rssstream.net, kterou jsem nechal padnout, a ktera byla porad volna. Nelenil jsem, regnul jsem a udelal vyhledavani v te me databzi:
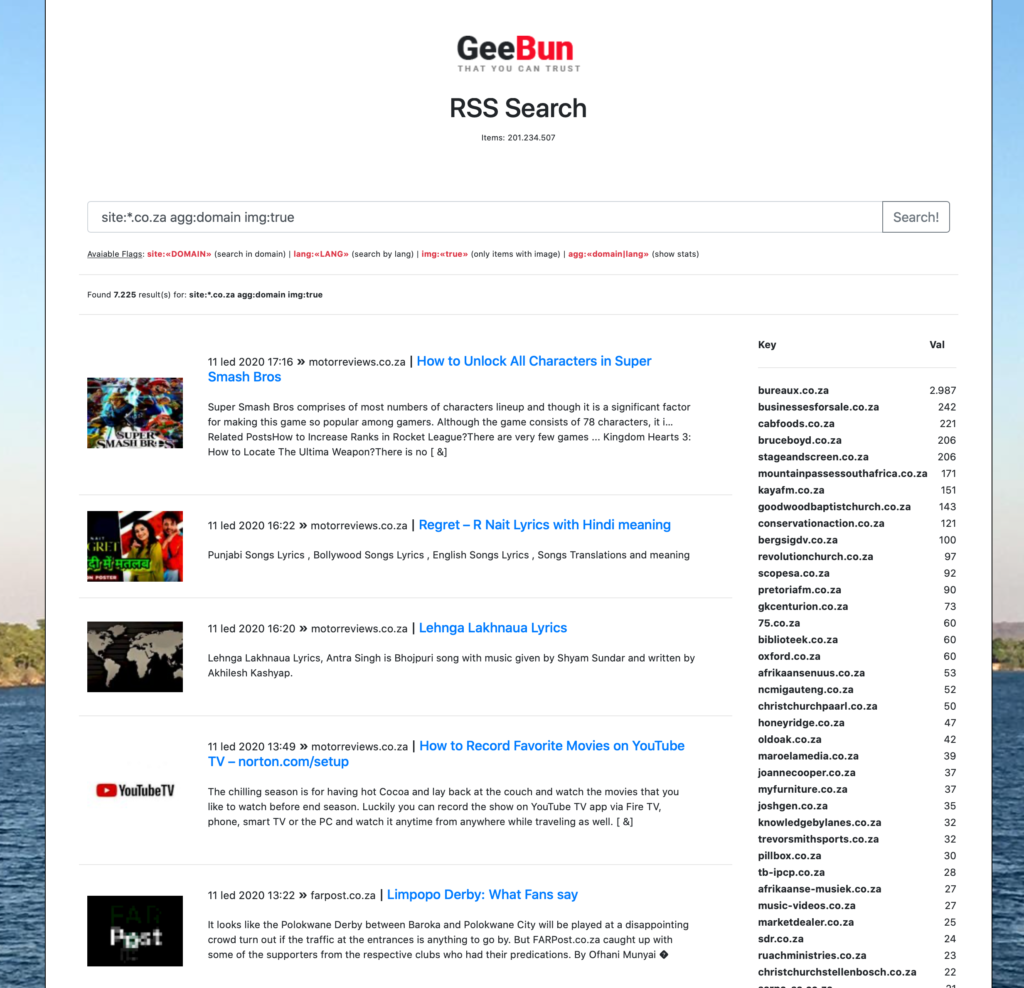
Krom vyhledavani mezi polozkama jsem pridal i par funkcni:
site:<DOMENA>
standardne vyhleda RSS polozky z domeny <DOMENA> … pokud jako prvni znak bude pouzita hvezdicka, pouzije se na vyhledavani wildcard, lze tedy vytahnout i weby z nasi domeny: site:cz
lang:<LANG>
ne vsechny weby v cestine ale jedou na .CZ domene, takze za pomoci lang:cs lze vytahnout clanky v cestine nehlede na domene 🙂
img:true
nektere RSS Feedy obsahuji ke kazdemu clanku i odkaz na nejaky obrazek, nemyslim obrazek webu/feedu, ale primo konkretniho clanku. Tento parametr pak nastavuje, ze se hledaji jen takoveto prispevky.
agg:<domain|lang>
Elastic nabizi uzasnou agregacni funkci, takze jsem pridal jako jeden z filtru i vyuziti teto agregace a zobrazeni prehledu. Agregace povoluji vuci “domain” nebo “lang“. Jakmile je parametr aktivni, zobrazi se na webu statistika vuci vyhledavacimu dotazu tak jako na screenshotu.
Zaver
Tak to by bylo pro tento tyden vse 🙂 Jak je videt, prace je tam spousta a reklamni systemy tyhle weby nemaj radi, ale ja se nevzdavam 😀